Tldr
这篇文章定义了现代 fuzzer 应该具备的功能,并提供了 Rust 实现,可以作为设计 fuzzer 的参考。
update
- 根据 Fuzzer 结构补充一些工作
看看能不能以 Fuzzer 结构为核心,整理总结一下模糊测试近年来的工作。
现代 Fuzzer 结构
作者提出了现代 fuzzer 的组成部分:
Input
- Input:程序的输入。重点是其在 fuzzer 内部的表现形式,最常见的就是 byte array,不过其不适用于一些特殊场景,比如 grammar fuzzer 会将输入存储为 AST 等结构,在发送给目标程序前才会序列化为字节序列。
- 相关工作:
- 实际上只要目标不能简单地输入字符串,那它几乎一定要自己处理输入。
- syzkaller - kernel fuzzer
- 通过生成系统调用 fuzz linux 内核
- NAUTILUS: Fishing for Deep Bugs with Grammars
- 语法 fuzzer
- Token-Level Fuzzing
- token 级别的 fuzzer
- FuzzIL: Coverage Guided Fuzzing for JavaScript Engines
- js fuzzer
Corpus
- Corpus:输入和其附属元数据的存储。
- 这个部分相关的工作不多,主要是需要考虑工程上的效率问题。
- 若位于内存中会导致较大的资源消耗(但是速度会快一些),若位于磁盘则方便用户观察 fuzzer 的状态,代价是速度受到磁盘读写的瓶颈制约,主流 fuzzer 大多选择后者。
- 此外,存储时还要区分有助于进化的 interesting testcase 和最终触发 crash 的 solution。
Scheduler
- Scheduler:从 corpus 中选取 testcase 的调度策略。
- 个人理解,因为 corpus 中的种子是越来越多的,因此怎样挑选最合适的种子是很重要的。
- 最朴素的即先进先出或随机选择,近年来也有工作利用调度来给 testcase 排优先级或是防止 testcase 爆炸。
- 相关工作
- Coverage-based Greybox Fuzzing as Markov Chain
- 最经典的 AFLFast,给能够给经过概率更低的路径的种子更高的能量。
- Directed Greybox Fuzzing
- 第二经典的 AFLGo,给函数距离与目标更近的种子更高的能量。
- Coverage-based Greybox Fuzzing as Markov Chain
Stage
- Stage:定义对单个 testcase 进行的操作(action)。
- 在 scheduler 选择了一个 testcase 后,fuzzer 会在其上进行分阶段的操作,比如 AFL 中的 random havoc stage 会对输入进行多种变异操作,许多 fuzzer 都有 minimization phase 以在保持覆盖率的同时减小 testcase,这也是一种 stage。
- 相关工作
- Angora: Efficient Fuzzing by Principled Search
- 在处理 testcase 时执行污点跟踪收集信息;
- Angora: Efficient Fuzzing by Principled Search
Observer
- Observer:提供一次执行目标程序的信息。从对 fuzzer state 的影响看,observer 的快照应当和执行本身应当是等效的,这样在分布式 fuzzer 或是执行很慢的目标程序上会比较有帮助。覆盖导向型 fuzzer 中常用的 coverage map 就是一种 observer。
- 简而言之是在执行一次模糊测试之后,用户能够得到的信息。
- 例如对于 AFL/LibFuzzer 就是 bitmap 中填充的数据(指代的是边覆盖率的信息)
- 相关工作:
- IJON: Exploring Deep State Spaces via Fuzzing
- 尽管它保存的不是边覆盖率的信息,但最终它还是将保存的信息映射为 hash map。
- FuzzFactory: Domain-Specific Fuzzing with Waypoints
- 除了覆盖率之外,还保存它自己定义的特定领域的反馈(domain-specific feedback)信息
- IJON: Exploring Deep State Spaces via Fuzzing
Executor
- Executor:用 fuzzer 的输入来执行目标程序。不同 fuzzer 在这方面区别可能很大,libFuzzer 这种 in-memory fuzzer 只需调用 harness 函数,Nyx 这种 hypervisor-based fuzzer 则每次执行都要从快照重启整个系统。
- 相关工作:
- libfuzzer:
- 通过定制
LLVMFuzzerTestOneInput执行 harness 函数;
- 通过定制
- Nyx: Greybox Hypervisor Fuzzing using Fast Snapshots and Affine Types
- 对虚拟机管理程序进行 Fuzzing
- libfuzzer:
Feedback
- Feedback:将程序执行的结果分类以决定是否将其加入 corpus。大多数情况下 Feedback 和 observer 紧密相连但又有所不同,feedback 通常处理一个或多个 observer 报告的信息来判断 execution 是否 “interesting”,是否是满足条件的 solution,比如可观测的 crash。
- 相关工作:
Mutator
- Mutator:从一个或多个输入生成新的 testcase。
- 这部分通常是定制 fuzzer 时最常改动的,不同 mutator 可以组合,往往还和特定的输入类型绑定,比如传统 fuzzer 中常见的是比特级别的变异,比如 bit flip 和 blocks swapping,而 grammar fuzzer 中的 mutator 则可交换 AST 上的节点来进行变异。
Generator
- Generator:凭空产生新的输入。有随机生成的,也有 Nautilus 这种基于语法的。
LibAFL 的实现
基于上面这许多抽象的定义,作者用 Rust 实现了 LibAFL,有三个主要组成部分:核心组件 LibAFL Core, 在目标程序中运行的 LibAFL Targets,提供编译 wrapper 的 LibAFL CC,除此之外还包含了几个插桩后端(Instrumentation Backends),下图描绘了 LibAFL Core 的架构:
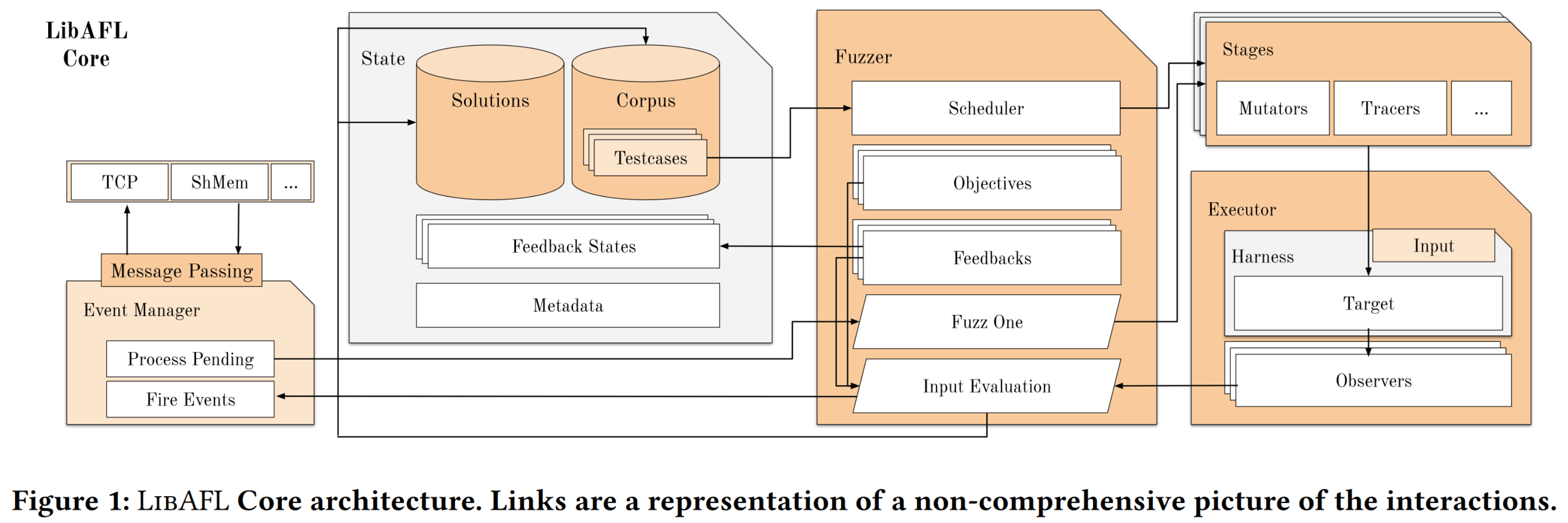
从图中可以看到 LibAFL 的组成部分,除了 State, Fuzzer 和 Events Manager 这三个大模块之外,大部分都一一对应前文所定义的 9 大实体。总之,模块化的设计让 LibAFL 天生具有极强的 Extensibility,基于 Rust 实现,独立于平台和不依赖标准库带来了 Portability,Event Manager 使得多节点并行 fuzz 的 Scalability 成为可能,这便是 LibAFL 设计之初所遵循的三个原则。
一些想法
- 可以看出 Observer 模块相当于一次程序执行之后能反馈的信息。对于可以获取覆盖率的程序显然就是覆盖率了,在此基础上还可以添加状态,就算是纯黑盒的协议 Fuzz 理论上也可以通过返回状态作为反馈信息。
- 如果有一些需要纯黑盒 Fuzz 还不一定有返回信息的该怎么办呢?
- Fuzz 确实不是万能的
- 但是这个需求也很奇怪吧!
- 如果有一些需要纯黑盒 Fuzz 还不一定有返回信息的该怎么办呢?
- Executor 也是现实实现中需要注意的点,对于某些无法模拟的固件或者很难模拟的固件,需要精心设计对应的 Executor。
- 如果想要 fuzz 的目标是一个带有状态机的协议(比如 SSH),那么该如何修改 libafl 进行适配呢?
- 看上去 afl 并不是为了 fuzz 协议实现的,是时候整理一下基于 afl 的协议 fuzz 了。
- 以及其他协议 fuzz
找时间结合源码看一下吧。
相关工作
在 libafl 的基础上有人实现了 feroxfuzz,一个黑盒 http 协议 fuzz。根据它的设计哲学:
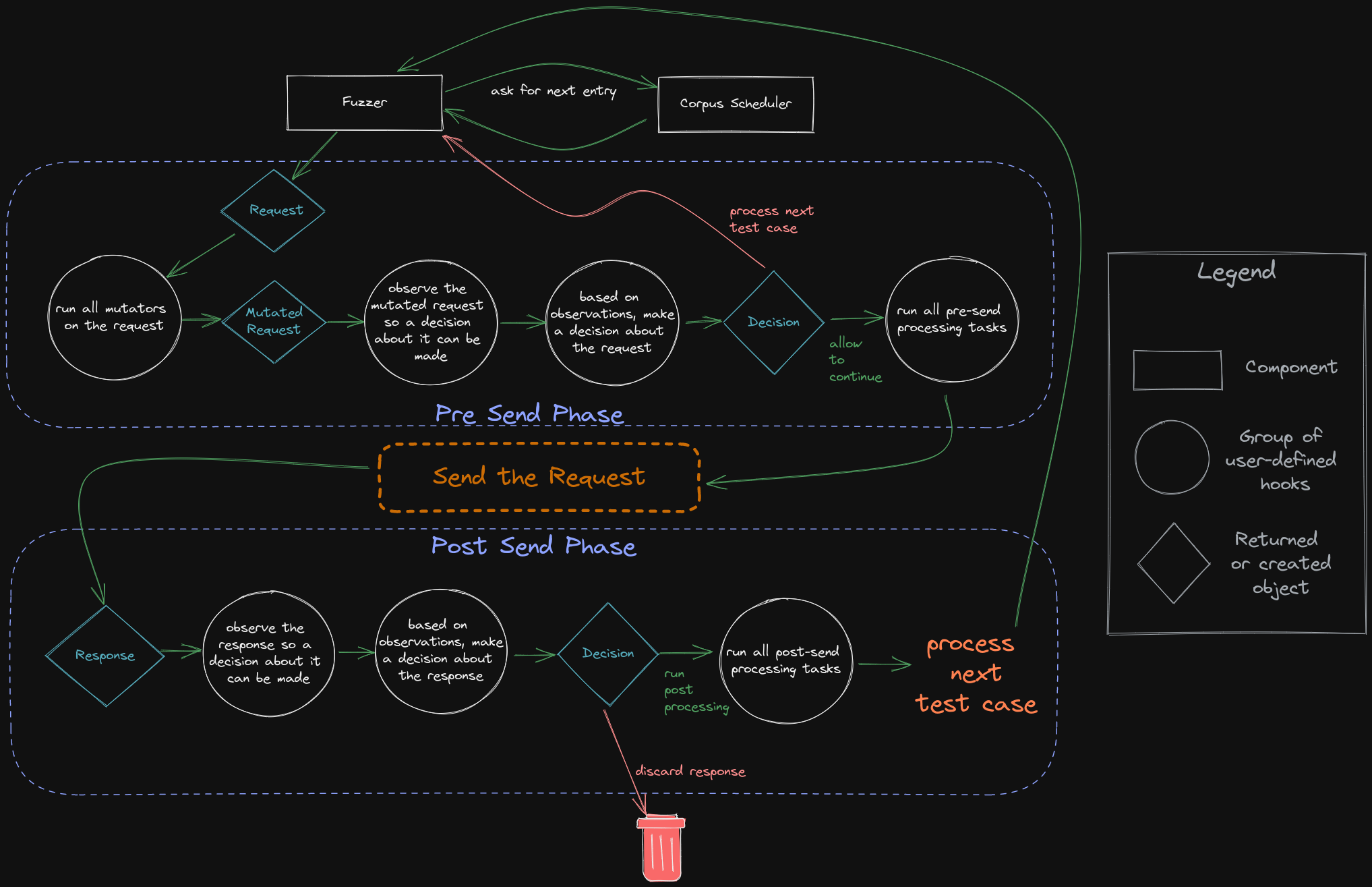
它将 response 作为 observer 传递给 feedback。