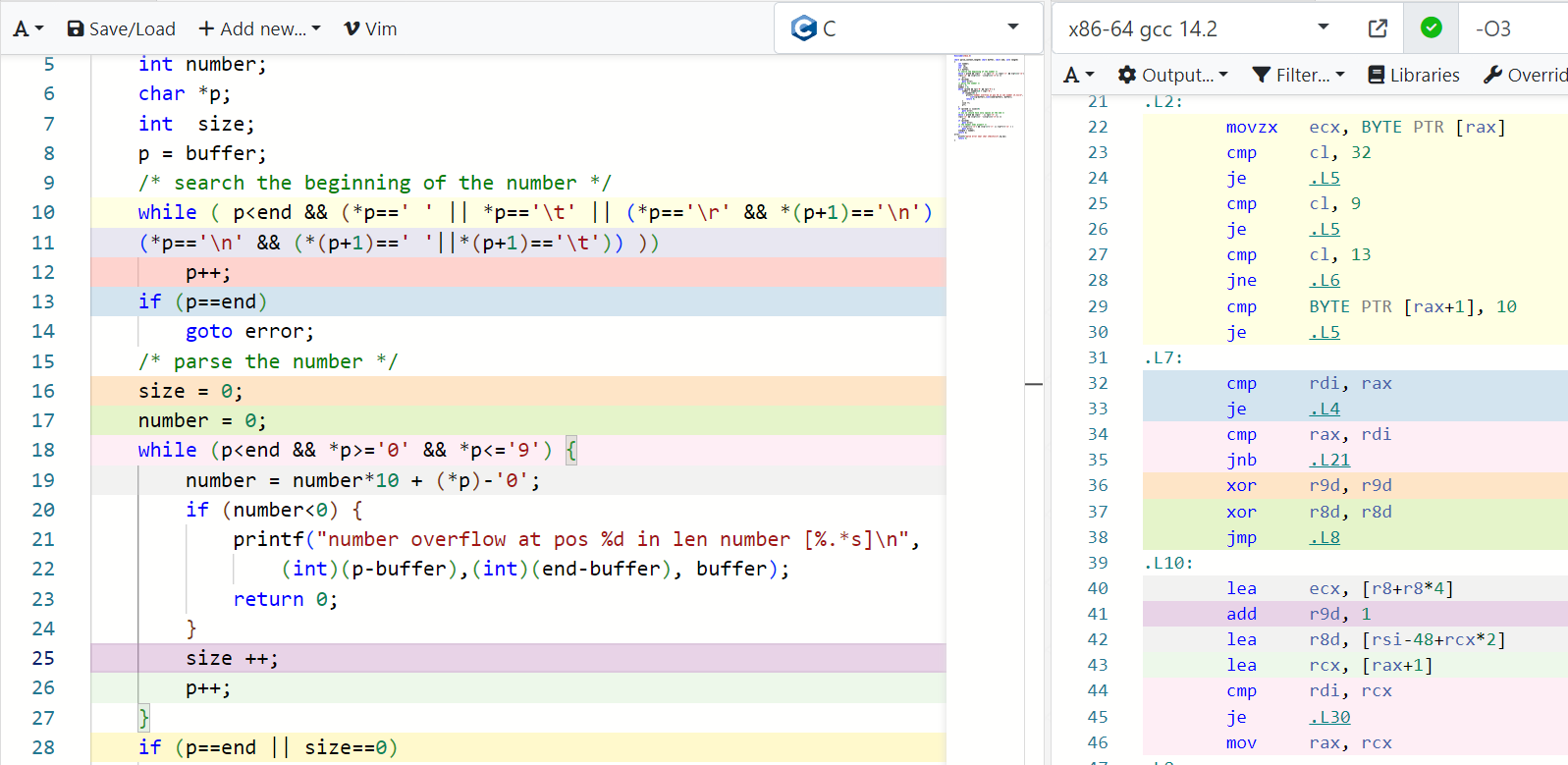
while (p<end && *p>='0' && *p<='9') { number = number*10 + (*p)-'0'; if (number<0) { LM_ERR("number overflow at pos %d in len number [%.*s]\n", (int)(p-buffer),(int)(end-buffer), buffer); return 0; } size ++; p++;}
Value ranges after Early VRP:
_1: long unsigned int [0, 10]
_2: int VARYING
number_3: int [number_13, number_13]
_4: int [48, 57]
_5: int [-2147483600, +INF]
_7: int [0, 10]
_8: long int VARYING
_9: int VARYING
_10: char VARYING
p_11: char * [1B, +INF] EQUIVALENCES: { p_12 } (1 elements)
p_12: char[11] * [&buffer, +INF]
number_13: int VARYING
size_14: int [0, +INF]
_19: signed long [0, 10]
end_22: char[11] * [1B, +INF]
number_23: int [-INF, 2147483599]
size_24: int [1, +INF]
p_25: char * [1B, +INF]
_32: int VARYING
_33: int VARYING
在推断出范围之后,对基本块做了一些操作:
Removing basic block 4
Merging blocks 3 and 5
Merging blocks 9 and 10
See also the -fwrapv option. Using -fwrapv means that integer signed overflow is fully defined: it wraps. When -fwrapv is used, there is no difference between -fstrict-overflow and -fno-strict-overflow for integers. With -fwrapv certain types of overflow are permitted. For example, if the compiler gets an overflow when doing arithmetic on constants, the overflowed value can still be used with -fwrapv, but not otherwise.
while (p<end && *p>='0' && *p<='9') { /* do not actually cause an integer overflow, as it is UB! --liviu */ if (number > 214748363) { LM_ERR("integer overflow risk at pos %d in len number [%.*s]\n", (int)(p-buffer),(int)(end-buffer), buffer); return 0; } number = number*10 + (*p) -'0'; size ++; p++;}
第二次修复就很正常了,首先用 INT_MAX 替换 214748363 避免不同平台上 int 定义不一致的问题,接下来给 ((*p)-'0') 加上括号,避免计算中间的 UB:
while (p<end && *p>='0' && *p<='9') { /* do not actually cause an integer overflow, as it is UB! --liviu */ if (number >= INT_MAX/10) { LM_ERR("integer overflow risk at pos %d in length value [%.*s]\n", (int)(p-buffer),(int)(end-buffer), buffer); return NULL; } number = number*10 + ((*p)-'0'); size ++; p++;}